Устранение неполадок¶
Физический узел в статусе enroll¶
Если после добавления физического узла его статус изменился на enroll, то возможны следующие варианты:
- Указанный IP-адрес недоступен с узла развёртывания. Проверьте доступность адреса с узла развёртывания: надо выйти из asperitas консоли и попробовать команду
ping -c 1 2.2.2.3
- Логин/пароль от BMC неверные
Чтобы изменить параметры узла, можно удалить узел и создать его заново или изменить параметры текущего узла. Для этого выберите узел в списке физических узлов и нажмите Enter или дважды кликните мышкой:
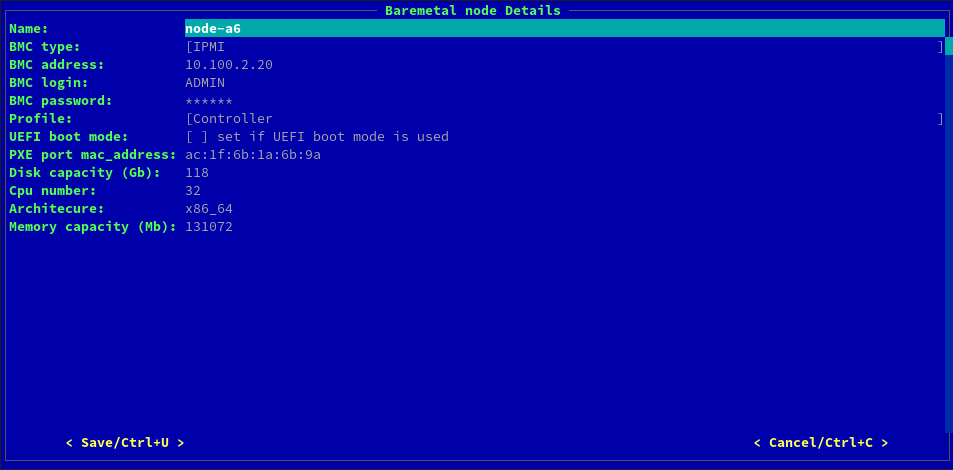
Измените необходимые параметры, а также снова введите пароль. Нажмите кнопку Save и ожидайте изменение статуса на manageable.
Ошибка интроспекции¶
DnsmasqFilter¶
Ошибка при попытке интроспектировать узел
The PXE filter driver DnsmasqFilter, state=uninitialized: my fsm encountered an exception: Can not transition from state 'uninitialized' on event 'sync' (no defined transition)
Описание проблемы есть на сайте RedHat Solutions Причина ошибки: драйвер pxefilter не может инициализировать DNSmasq Решение: перезапустить все сервисы Ironic
for service in $(sudo systemctl | grep tripleo_ironic | cut -d " " -f3) ; do sudo systemctl restart $service ; done
Ramdisk error¶
2024-02-26 19:16:12.688 7 ERROR ironic_inspector.utils [-] [node: MAC 00:25:90:bb:0e:d8 BMC 10.100.2.33] Ramdisk repor
ted error: The following errors were encountered:
* failed to run hardware-detect utility: [Errno 2] No such file or directory: 'hardware-detect'
2024-02-26 19:16:12.688 7 ERROR ironic_inspector.process [-] [node: MAC 00:25:90:bb:0e:d8 BMC 10.100.2.33] Hook ramdis
k_error failed, delaying error report until node look up: Ramdisk reported error: The following errors were encountere
d:
* failed to run hardware-detect utility: [Errno 2] No such file or directory: 'hardware-detect': ironic_inspector.util
s.Error: Ramdisk reported error: The following errors were encountered:
Смотреть логи в /var/log/containers/ironic-inspector/ramdisk
No valid JSON при создании развёртывания¶
Ошибка при создавнии развёртывания
ValueError: Value must be valid JSON: Expecting value: line 1 column 1 (char 0)
На узле развёртывания выполните
sudo podman exec -ti -u root heat_engine vi /usr/lib/python3.6/site-packages/heat/engine/parameters.py
Найдите класс JsonParam и исправьте функцию parse:
message = _('Value %s must be valid JSON: %s') % (value, err)
Затем перезапустите контейнер
sudo systemctl restart tripleo_heat_engine
И запустите создание заново
Параметр не определён или определён неправильно в шаблоне¶
Если при создании стека не хватает какого-то параметра, но при этом, стек уже начал создаваться. Или если результат не соответствует указанному в параметре. То можно использовать следующие команды для дебага
openstack stack environment show asperitas
openstack stack template show asperitas
При раскатке конфигурации (config-install) не найден плейбук¶
Если при развёртывании облака вы видете ошибку,
RuntimeError: No such playbook: /home/stack/config-download/best-deployment-ever/deploy_steps_playbook.yaml
То зайдите в папке /etc/asperitas/templates/deploy в последний файл с именем вашего деплоя.
Далее выполните
grep -RIins OS::TripleO::PostDeploySteps
Если в выводе присутствуют записи вида OS::Heat::None - то удалите их и обновите стек.
Пояснение¶
При операции config download выполняется генерация плейбуков.
Код находится в библиотеке tripleo_common в папке utils/config.py.
Для дебага можно использовать команду
openstack overcloud config download --debug --name <deploy_name>
Функция отвечающая за непосредственную генерацию файлов называется write_config.
Она использует stack outputs сгенерённые при создании стека.
А именно для генерации deploy_steps_playbook.yaml используется ресурс RoleConfig.
Поэтому если в стеке обнулён ресурс PostDeploySteps, то и плейбук не будет сгенерён.
Ошибка настройка сети¶
Если при развёртывании облака вы видете ошибку,
"failed_when_result": true
}
2023-03-02 17:02:49.089226 | 08002710-c16f-44d5-9117-00000000029d | TIMING | NetworkConfig stdout | monitoring-ceph-0 | 0:05:58.946554 | 0.06s
зайдите на упавший хост по ssh и выполните
sudo cat /etc/os-net-config/config.json
В выводе будет сгенерённый для вашего узла сетевой план. Проверьте, что план соответствует ожидаемым настройкам . Если план не соответствует, то перейдите к настройке сетевого плана снова и запустите обновление развёртывания.
Если план соответствует ожидаемому, то выполните
sudo os-net-config -c /etc/os-net-config/config.json --verbose
И посмотрите на вывод команды и ошибки, которые команда выведет. Дальнейшая работа с проблемой зависит от ошибок в выводе команды.
После исправления всех ошибок, с узла развёртывания выполните
screen -x <deploy_name>
INTERACTIVE MODE
Enter command: c
Развёртывание продолжится дальше
Puppet cache read-only файловая система¶
Если при развёртывании падают контейнеры вида container-puppet-
sudo less /var/log/containers/stdouts/container-puppet-<service>.log
Если видны ошибки вида
boost::filesystem::remove: Read-only file system: "/opt/puppetlabs/facter/cache/cached_facts/kernel"
то проблема скорее всего в том, что развёртывание было начато некоторое время назад и кеш успел измениться.
Необходимо пересоздать один из упавших контейнеров container-puppet-
sudo podman ps -a
#использовать вывод для пересоздания контейнера
sudo podman inspect container-puppet-<service> | | jq .[0].Config.CreateCommand
sudo podman rm container-puppet-<service>
sudo podman container run <...> --volume /var/lib/container-puppet/puppetlabs:/opt/puppetlabs:rw <...>
Остальные упавшие контейнеры вида container-puppet-
sudo podman restart container-puppet-<service>
Неправильные права на директорию при развёртывании с использованием Ceph¶
Ошибка выглядит следующим образом
2023-03-27 20:34:52.505694 | 52540064-5093-800d-24d6-00000001f15c | TASK | symbolic link to tripleo inventory from ceph-ansible work directory
2023-03-27 20:34:52.764361 | 52540064-5093-800d-24d6-00000001f15c | IGNORED | symbolic link to tripleo inventory from ceph-ansible work directory | undercloud | error={"changed": false, "msg": "Error while linking: [Errno 13] Permission denied: b'/home/stack/config-download/asperitas/tripleo-ansible-inventory.yaml' -> b'/home/stack/config-download/asperitas/ceph-ansible/inventory.yml'", "path": "/home/stack/config-download/asperitas/ceph-ansible/inventory.yml"}
2023-03-27 20:34:52.765518 | 52540064-5093-800d-24d6-00000001f15c | TIMING | tripleo_ceph_work_dir : symbolic link to tripleo inventory from ceph-ansible work directory | undercloud | 3 days, 3:22:28.851303 | 0.26s
С узла развёртывания выполните
sudo chown -R stack:stack config-download/config-download-latest/ceph-ansible
screen -x <deploy_name>
INTERACTIVE MODE
Enter command: re
Wait for puppet host configuration to finish¶
Если при развёртывании сервисов Ansible падает на задаче Wait for puppet host configuration to finish, то сначала необходимо определить узел, на котором произошла ошибка
YYYY-MM-DD HH:MM:SS | 00000000-0000-0000-0000-000000000000 | WAITING | Wait for puppet host configuration to finish | asperitas-controller-0
В примере выше ошибка произошла на узле asperitas-controller-0. Для поиска причины ошибки необходимо зайти по ssh на этот узел и запустить puppet самостоятельно
sudo puppet apply --modulepath=/etc/puppet/modules:/opt/stack/puppet-modules:/usr/share/openstack-puppet/modules --detailed-exitcodes --summarize --color=true --verbose --debug /var/lib/tripleo-config/puppet_step_config.pp
Дальнейший поиск проблемы зависит от вывода команды.
Если вывод команды долгий или недостаточно информативный, то добавьте флаг --debug
Pacemaker¶
Ошибка выглядит следующим образом:
Error: 'pcs status | grep -q -e "asperitas-novacomputeiha-30[[:blank:]].*Started"' returned 1 instead of one of [0]
Это значит, что pacemaker не смог запустить ресурс asperitas-novacomputeiha-30.
С любого из контроллеров выполните:
sudo pcs status
Вы увидите статус FAILED для ресурса asperitas-novacomputeiha-30. Проверьте правильность его настройки:
sudo pcs resource config asperitas-novacomputeiha-30
В выводе будет указан адрес ресурса в поле Attributes.
- Проверьте доступность адреса с узла контроллера, на котором вы сейчас находитесь.
ping -c 1 <ip>
- Проверьте, что на этот адрес ходят большие пакеты
ping -c 1 -s 10000 <ip>
- Проверьте, что доступен порт 3121. Запрос не должен виснуть и не должен выводить ошибку Failed to connect
curl <ip>:3121
Если порт не доступен, то зайдите на проблемный узел по ssh и проверьте статус сервиса pacemaker_remote
sudo systemctl status pacemaker_remote
Этот сервис должен быть активен только на узлах виртуализации. На узлах контроллерах должен быть активен сервис pacemaker.
Если сервис активен, но имеет ошибки вида
error: TLS handshake with remote client failed: An illegal parameter has been received.
то скопируйте файл /etc/pacemaker/auth с рабочего узла. Команды с узла развёртывания
ssh heat-admin@<working-host>.ctlplane 'sudo cp /etc/pacemaker/auth ./'
rsync -azP heat-admin@<working-host>.ctlplane:authkey ./
rsync -azP authkey heat-admin@<failed-host>.ctlplane:
ssh heat-admin@<failed-host>.ctlplane 'sudo cp authkey /etc/pacemaker/'
После решения проблем зайдите на любой из контроллеров и выполните
sudo pcs resouce refresh <failed-host>
В указанном выше примере failed-host == asperitas-novacomputeiha-30.
Запустите повторно puppet на узле, на котором puppet упал изначально. Если puppet выполнит работу без ошибок, то продолжите работу Ansible далее без повторного выполнения задачи Ansible.
Не найден хост¶
После обновления развёртывания¶
- Переведите nova-scheduler в режим debug. Для этого поменяйте параметр debug=False в True в файле /var/lib/config-data/puppet-generated/nova/etc/nova/nova.conf. Затем перезапустите nova-scheduler
sudo systemctl restart tripleo_nova_scheduler
- Попробуйте создать виртуальную машину и проверьте в логах ошибку
less /var/log/containers/nova/nova-scheduler.log
Если ошибка выглядит следующим образом,
Filter AllHostsFilter returned 0 host(s)
то зайдите на любой контроллер (только один!) и выполните
sudo podman exec -ti -u root nova_compute nova-manage placement heal_allocations
sudo podman exec -ti -u root nova_compute nova-manage placement sync_aggregates
Число используемых ресурсов на гипервизорах обнулилось¶
Такое может произойти, если вы попытались поменять основной домен для имен хостов. В таком случае вы увидете следующее.
Например, вы поменяли хостнейм с localdomain на novalocal, тогда
openstack server list --all-projects --host asperitas-novacomputeiha-12.localdomain -f value | wc -l
20
openstack hypervisor show asperitas-novacomputeiha-12.novalocal -c service_host -c running_vms
+--------------+-----------------------------------------+
| Field | Value |
+--------------+-----------------------------------------+
| running_vms | 0 |
| service_host | asperitas-novacomputeiha-12.localdomain |
+--------------+-----------------------------------------+
Причина проблемы в том, что у виртуалок запущенных на хосте asperitas-novacomputeiha-12.localdomain есть параметр гипервизора, который остался в значении asperitas-novacomputeiha-12.localdomain.
Чтобы решить проблему, необходимо на любом из контроллеров зайти в базу данных Mariadb и поменять значение для виртуалки
sudo podman ps | grep galera
ab09fec32c4b undercloud.ctlplane:13787/image/docker../../../images/ispras/minos/openstack-mariadb:pcmklatest /bin/bash /usr/lo... 9 days ago Up 8 days ago galera-bundle-podman-0
sudo podman exec -ti -u root galera-bundle-podman-0 mysql
> use nova_api
> select display_name from instances where node='asperitas-novacomputeiha-12.localdomain' and deleted_at is null;
> begin;
> update instances set node='asperitas-novacomputeiha-12.novalocal' where node='asperitas-novacomputeiha-12.localdomain' and deleted_at is null;
> commit ;
Бекенд для cinder недоступен¶
Если бекенд находится в статусе down при выполнении команды
openstack volume service list
Сначала проверить доступность бекенда с узлов, пароли, МТУ сети. Затем
openstack volume service set --disable hostgroup@tripleo_ceph_reliable cinder-volume -vv
pcs resource restart openstack-cinder-volume
openstack volume service set --enable hostgroup@tripleo_ceph_reliable cinder-volume -vv
Вычислительный узел не добавлен в nova_cell¶
Если на вычислительном узле в логах /var/log/containers/nova/nova-compute.log ошибка выглядит следующим образом:
ERROR nova.cmd.common [req-4431a4a0-6789-466f-9ed1-b518a05b5771 - - - - -] No db access allo
wed in nova-compute: File "/usr/bin/nova-compute", line 10, in <module>
То скорее всего вычислительный узел был развёрнут без undercloud узла в консоли - нужно развернуть с ним вместе.
Ошибка миграции Host key verification failed¶
Быстрый метод решения проблемы
sudo su
echo 'StrictHostKeyChecking no' >> /var/lib/config-data/puppet-generated/nova_libvirt/var/lib/nova/.ssh/config
systemctl restart tripleo_nova_compute
Виртуальная машина в статусе ERROR¶
Если виртуальная машина перешла в статус ERROR, то необходимо Выяснить на каком узле находится машина
openstack server show -c OS-EXT-SRV-ATTR:host <server_id/name>
Зайти на узел и выяснить ошибку. Варианты могут быть следующие:
- Память
free -mh
- Дисковая память
df -h
- Статус контейнеров
sudo podman ps | grep nova
- Логи контейнеров
ls /var/log/containers
После выяснения всех ошибок и исправления их проверьте существование ВМ на этом узле, а именно
ls /var/lib/nova/instances/<server_id>
Затем верните ВМ в работающее состояние
openstack server set --state active <server_id/name>
openstack server stop <server_id/name>
openstack server start <server_id/name>
Если машина снова перешла в состояние ERROR, значит ошибка не исправлена - продолжайте исследовать
Libvirt ошибка секрета¶
При создании виртуальной машине в логах узла виртуализации /var/log/containers/libvirt/ видна ошибка
Secret not found: no secret with matching uuid
Выполните на узле
sudo podman exec -ti -u root nova_libvirt virsh secret-list
sudo podman exec -ti -u root nova_libvirt virsh secret-undefine <secret_uuid>
sudo podman exec -ti -u root nova_libvirt virsh secret-define /etc/nova/secret.xml
sudo podman exec -ti -u root nova_libvirt virsh secret-set-value
Причина ошибки - смена fsid для ceph’а, необходимо удалить старый fsid и добавить новый указанными выше командами